“Engineers...are not super human. They make mistakes in their assumptions, in their calculations, in the conclusions. That they make mistakes is forgivable; that they catch them is imperative. Thus it is the essence of modern engineering not only to be able to check one’s own work, but also to have one’s work checked and to be able to check the work of others. In order for this to be done, the work must follow certain conventions, conform to certain standards and be an understandable piece of technical communication.”
—[Petroski1982], p. 52
A solo programmer, working alone, has little need to adopt anything resembling consistent coding conventions. When no one else will ever see your code, you are the only person to benefit from any consistencies, or to have your progress hampered by any inconsistencies.
Some large, multi-programmer shops sidestep the issue by partitioning developers into “silos,” assigning each of them exclusive ownership of some subset of the master source for a project; as long as interfaces are clearly established between subsystems, it does not matter a whit to them if the developers follow the same, or even similar conventions. However, in the world that we inhabit, we consider our consistent coding style a strategic strength; the ease with which our engineers can easily slip from language to language, project to project, and platform to platform gives us the ability to remain agile and highly responsive to the changing needs of our clients.
This document is an extension of a programming style guide originally developed by Steve Sontag. It contains additional ideas and comments borrowed from many sources. Many links in this document refer to our Reliable Software Engineering Practices document for their rationale. A periodic reading of that document as well as this one, and adherence to the practices therein described, is highly recommended for all software engineers.
This document uses the same conventions as our Reliable Software Engineering Practices document.
In an ideal world, this document would tell you everything you need to know about the conventions used to write code while working here. However, this world is not the ideal one. When a client specifically requests that we adopt their coding conventions when working on their project, we will do so happily. In fact, the opposite case happens far more frequently, and more than a few current and former clients have adopted these style guidelines (or a style derived from ours).
There may also be other reasons to deviate from this style guide. Consistency of programming style is important, but we must not encourage a foolish consistency. When deviations are appropriate, seek first to maintain consistency within each individual line of source, then within each function, each source file, and each project. In other words, deviations from these guidelines should be kept as localized as possible.
Also, this document must be restricted to speaking in fairly broad strokes; its main goal is to illustrate the conventions to follow in the most common cases. Any project of significant size may wish to establish additional, local conventions to extend (but not replace) the practices outlined here. As an example, a large project that uses a complex class hierarchy would likely develop and consistently use a logical naming convention for the project. Once developed, any project-specific conventions should be documented in the project’s ProjectParticulars.txt file.
Software is typically generated from text files. The contents of these text files are typically referred to as “source code.” Because, for the sake of a compiler, this text needs to follow a well defined and (sometimes) terse syntax (as defined by the chosen programming language), it can well be considered “code.” However, because it is also written and read by us mere mortals, the more like “a code” it is, the more likely it is to contain errors. It is therefore common to make source code read as close as possible to a natural language (usually English). Our Reliable Software Engineering Practices, along with this “English like” mandate, are our guiding principles when it comes to choosing our stylistic preferences.
One of the other significant changes from earlier versions of these guidelines is organizational. This document is now organized based on an “orbital” view of our typical projects. It starts fairly broad and continues to drill down to finer and finer levels of detail as it progresses.
Our original version of these guidelines was explicitly written for C++. However with Apple’s release of Cocoa, it became necessary to expand our coverage to more than one language. Thus these style guidelines are intended to be somewhat polyglot.
The languages that should be coded according to the principles outlined in this guide include the primary programming languages we use, viz.:
The examples in this document are intended to be as inclusive as possible; we count on the common sense of each engineer to ignore sections of this document that cover features not found in their current language (for example, any discussions of C++ template formatting will obviously have no impact on C or Objective-C programmers).
Similarly, we count on the common sense of each engineer to intelligently extrapolate the examples shown here to other languages that have features or constructs similar to those shown in the examples (e.g., the rules for ordering #import statements in Objective-C should be applied directly to the ordering of #include statements in C or C++.)
We also count on the common sense of our engineers to approach any work done in languages other than those in the above list (for example some scripting language) by working to maintain the spirit of these guidelines, extending our style by applying the principles laid out here (and in our Reliable Software Engineering Practices document).
While these style guidelines attempt to discuss programming style in as universal a way as possible, we also admit that each language we use will require some amount of specialization to adapt to the features, abilities, or oddities unique to it. As a rule, we do not work with languages that stray too far from the ALGOL tree, so this approach works without too much difficulty. If we did a large amount of work in LISP, Forth, Smalltalk, or other languages that originate in different schools of thought, we might need to approach this issue differently.
This document contains numerous code snippets to illustrate the points being made. These examples may be in any programming language covered by these guidelines. Many of them are not complete pieces of code, and we count on the reader to supply the missing context that would permit these snippets to make sense.
In this document, code examples are formatted like this.
One of the problems frequently faced by programmers is: “What do I do when I encounter code that does not adhere to the guidelines?”
For starters, you should rarely change headers (or other code) from libraries that were generated outside our company. Doing so becomes a significant maintenance hassle as those libraries are brought up to date.
However, within our code, one of the first questions that must be asked is: “Why weren’t the guidelines followed to begin with?” If the original author had a good reason to stray, it should be obvious or there should be a short comment hinting at the reasons for the deviation. However, if the original author is notorious for ignoring the guidelines, then they better understand that their code is likely to be changed (as time permits) into compliant code by others. (Of course, if they keep writing non-compliant code, they are likely to not work here very long. We certainly do not want to pay to do things twice, particularly when they can be avoided by conscientiousness.)
More to the point, however, during the Development and Alpha stages of a project, when one finds code that strays from the guidelines, there are several things to consider:
You should never correct mere style violations during Beta and Final Candidate stages, nor will you likely want to correct even poor engineering practices unless they are a contributing factor of a reported bug you are correcting.
If you consistently run across a coding situation that is not addressed by these guidelines and you feel the team would benefit from an appropriate guideline for that situation, you should write up a description of the situation, a guideline that will address it and any engineering practices it promotes, and e-mail it to your project’s manager. He will submit it to the maintainer of this document for consideration. If your suggestion is not added, the maintainer will reply with an e-mail providing the rationale for why it was rejected.
The largest unit of code organization is the repository. This is so primarily because we rely on version tracking; that is to say we keep track of the various versions of each file we generate. Consult our Repository Layout Guidelines for information about how repositories are organized and our typical project folder layout. It provides a standardized hierarchy so information is easier to find.
It should be expected that, at some future date, everything stored in a repository will be handed over to the client, so be careful you do not store private information (such as negotiation information, contracts, etc.) in the repository.
The next largest unit of code organization is the project. As a rule, code does not get written unless it is part of a project, whether for an external client, a library or for internal use. Every project we work on should have a certain set of common features that allow new programmers to integrate smoothly into the workflow.
The various files that make up a project, including documentation meant for delivery to the client or end users, should be stored as part of a version control system.
Every project should have a plain, ASCII text file named ProjectParticulars.txt.
This file should be located as shown in the Repository Layout Guidelines.
It is intended primarily for use by the engineering team and is excluded from any deliverables that will be deployed to end users.
The ProjectParticulars.txt file should be the primary source of information likely to be needed by an engineer working on the project.
Things that should be documented in a project’s ProjectParticulars.txt file include (but are not necessarily limited to):
New team member: ”I installed the SDK, and downloaded all the project source, but I still can not get things to link.”
Project manager: ”Oh, of course not. You need to {change a registry setting | change a compile option | set a path}.”
As the project evolves, the project manager is responsible for maintaining this document.
Every project needs to have a documented, repeatable release procedure.
(How would we recover if the team member responsible for this was killed in a car crash on the way home tonight?)
At the very least, a list of steps that must be performed in order to issue a release to the client needs to exist in the ProjectParticulars.txt file.
The preferred approach is to create a release procedure (as automated as reasonable) that implements the steps required to construct and prepare a release of the project for the client (or other end users of the project).
Common steps performed as part of a release procedure include:
ProjectParticulars.txt file.We assign version numbers to software releases using a scheme similar to that used by Apple. Every version number consists of three parts, followed by an optional release stage and number, like this:
<major>.<minor>.<patchlevel>[<stage><release>]
The <major> number is used to indicate major changes to the visible interface.
For instance, if a new release of a code library (or framework) has a different interface (and thus is expected to break existing clients) then it should have a new <major> number.
The <major> number should not be incremented for bug fixes, even when those bug fixes may break some programs, because it is a bug for a program to depend upon another bug.
The <minor> number should be incremented whenever a new feature (or set of new features) is added, but the new version of the application, library or framework remains backward compatible.
For libraries and frameworks, this means any client binary that works with a previous version of a <minor> number will continue to work with a new version having the same <minor> number.
For both applications and libraries, this means that any existing data files, environment variable names, user preferences, etc., that the program reads will be usable with the new version.
When the <major> number increments, the <minor> number is reset to zero.
The <patchlevel> number should be incremented whenever a bug is fixed, or as part of a build in the development cycle.
No incompatibilities with existing clients or file formats are introduced, neither reading nor writing.
When the <minor> number increments, the <patchlevel> number is reset to zero.
Often times, when the <patchlevel> number is zero, it and its preceding ‘dot’ are omitted (e.g., 1.5a01).
The possible values for the <stage> code are:
<stage> |
Description |
d |
Development release: Features are incomplete; typically the release is only a status update. |
a |
Alpha release: Feature complete; however the release may crash or hang. |
b |
Beta release: Project is substantially complete and ready for testing in the field; the only changes currently being made are in response to specific bugs reported in the defect tracking system. |
f |
Final candidate release: Candidate for final client approval; the only changes currently being made are in response to specific bugs that must be fixed before the client will accept the final candidate. |
The <stage> code and <release> number are used while a project is under development.
While in each stage of a version’s lifecycle, any release that is issued indicates both the stage and sequence of the release, with <release> numbers for each <stage> starting at 01.
Programmers can learn what will be the next version tag for a given project by looking at the ProjectParticulars.txt file.
Once a client accepts a final candidate, a version is released bearing an identical version identifier without the <stage><release> portion.
The only allowable source difference between version X.Y.Zf# and X.Y.Z is the version number itself.
Every project should enable compiler warnings appropriate to the language(s) being used. (Although we do expect warnings to be addressed and eliminated, we typically do not enable a compiler option that “treats warnings as errors.”)
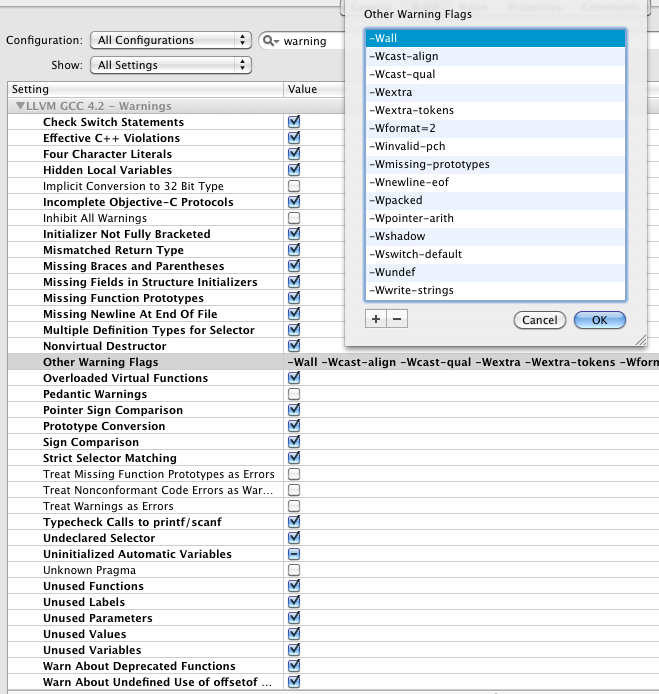
Within Xcode, when developing for any C-based language, we recommend the following for the “Other Warning Flags” (aka [WARNING_CFLAGS]) build setting:
-Wall -Wcast-align -Wcast-qual -Wextra -Wextra-tokens -Wformat=2
-Winvalid-pch -Wmissing-prototypes -Wnewline-eof -Wpacked -Wpointer-arith
-Wshadow -Wswitch-default -Wundef -Wwrite-strings -W
We also recommend considering adding these warning flags:
-Wfloat-equal // Cf. our FloatEquality.h file for alternatives
Although the above provides many useful warnings, there are other settings that—when added directly to the “Other Warning Flags” build setting—become problematic (because other language files cause spurious warnings). Therefore, we recommend using the Xcode UI (which is clever enough to avoid the inappropriate warnings) to always check the following:
-Weffc++) (Some standard library headers may not conform, so use discernment.)-Wfour-char-constants) (but some programs may require this off)-Wno-protocol)-Wselector) (but some programs may require this off)-Woverloaded-virtual)-Wpointer-sign)-Wconversion) (but this will cause lots of otherwise unnecessary casting)-Wstrict-selector-match) (but some programs may require this off)-Wundeclared-selector)-Winvalid-offsetof)It can also be useful to periodically validate your code having these warning flags appended to the “Other Warning Flags” (aka [WARNING_CFLAGS]) build setting:
-Wdisabled-optimization // for release builds
-Winit-self // for builds with optimization -O1 or better
-Wmissing-noreturn
-Wpadded
-Wredundant-decls
Given the above, the following Xcode build settings do not have to be checked (although, if they are, it does not hurt). They are already part of -Wall and -Wextra:
-Wswitch)-Wshadow)-Wmissing-braces)-Wreturn-type)-Wparentheses)-Wmissing-field-initializers)-Wmissing-prototypes)-Wnewline-eof)-Wnon-virtual-dtor)-Wsign-compare)-Wformat)-Wuninitialized) (requires some form of optimization)-Wunused-function)-Wunused-label)-Wunused-parameter)-Wunused-value)-Wunused-variable)-Wdeprecated-declarations)Here is a screenshot of a typical set of warnings in the Xcode UI:
Within Xcode, we recommend the following C++ specific options for the “Other C++ Flags” build setting:
$(OTHER_CPLUSPLUSFLAGS) -Wold-style-cast
Within Xcode, we recommend the following Objective-C specific options for the “Other Warning Flags” build setting when none of your files use Objective-C++:
-Wmissing-declarations -Wnested-externs -Wold-style-definition -Wstrict-prototypes
More experience is needed before generating useful style guidelines regarding namespaces and their usage.
Prefer to always have a single class or concept per source file. An obvious exception to this is when developing exception or other classes that are tightly coupled to a specific class (in effect, becoming part of its interface). As Sutter states in Item 32 of [Sutter2000]:
”For a class X, all functions (including free functions) that both
…are logically part of X, because they form part of the interface of X.”
It may also make sense to group together a collection of small utility classes into a single source file.
Source files containing the interface or implementation of a single class should have the same name and capitalization as the class.
For example, the interface (aka header) file for the Objectrive-C class AboutBox would be AboutBox.h, and the implementation file would be AboutBox.m.
Source files that contain more than a single class should use the name of the primary class (if the other classes play a subsidiary role), or a descriptive name that clearly identifies the contents or concept of the file.
Every source file should begin with a comment that includes the copyright claim for that file.
Our standard contract allows us to retain copyright on code that is not specific to a project; any other code should claim a copyright on behalf of the client.
For example, code to read and parse a generic, tab-delimited file should retain the copyright in our name, but code to read and parse a data file using a client’s proprietary format should use the client’s copyright.
If in doubt, consult the ProjectParticulars.txt file or the project manager.
All source files that retain the copyright in our name should include text similar to the following in a comment as close to the top of the file as possible:
// =======================================================================================
// File: Stationery.h
// Created: 2004/Apr/12
// Modified: See SVN $LastChangedDate information at the bottom of the file.
//
// Copyright: (c)2004-2005 Steve Sontag; all rights reserved.
// A non-exclusive license *may* be granted (as provided by contract).
//
// Note: The use and handling of this source code is subject to strict
// confidentiality procedures. Clients are cautioned against making unreviewed
// changes to the code, which could impair the functioning of the software.
// =======================================================================================
In the above comment block, all alignment is handled with spaces; not with tabs. Also, the first copyright year reflects the year the file was created, and the last year reflects the year the file was last modified. If the years are identical, the year still appears twice.
Often times, in an interface file, immediately following this copyright notice, you will find comments describing the general use and purpose of items in the interface.
The ProjectParticulars.txt file (or project manager) can provide the exact text to use for the client’s copyright statement.
When including or importing interface (aka header) files into another file, the statements that perform that inclusion should generally be grouped together as the first non-comment items in the file, with general files listed last:
For example, on an Objective-C project your files might be grouped something like this:
#import "ThisFile.h"
#import "GraphicDocument.h"
#import "DrawingView.h"
#import "Error.h"
#import <GCDrawing.h>
#import <WebKit/WebKit.h>
There are some obvious exceptions to the above:
By placing a given implementation file’s interface file first in the list, checking the compilation of the interface is easily accomplished by checking the compilation of the implementation file; all errors/warnings due to the interface will appear before those for the implementation file.
Also, we have system-defined files follow project specific files because a project specific file may already have included an otherwise necessary system-defined file. This tends to shorten the list and simplifies the order making it always “specific to general.”
Whenever possible, use a forward declaration of a class in an interface file instead of #including the class’s header, which has the complete definition. Although this is not always possible, when it is, it can significantly reduce compile times.
When using a language (like C++) which allows inline functions in an interface file, the inline functions should never be defined within a class definition; this causes unnecessary clutter, making it harder to understand the class and what it provides. (It also makes it more difficult to later move the inline implementation into the implementation file.) Instead, inline functions should be defined after everything else in the interface file, following a comment as follows:
// =======================================================================================
// Everything below this line is considered an implementation detail; as such, clients
// should *not* rely upon it. It is included here, however, to improve runtime efficiency.
// =======================================================================================
Exception: The one exception is providing an inline empty destructor definition within the class definition of a class that has no base class(es) and no member variable(s). Typically, such a class is an abstract base class. See also Item 8 of [Sutter2005a].
Every project should use some means of version tracking for the source files that make up the project. Although we currently use Subversion as our principal (and only) method of version tracking, a user may have to check with a project’s manager to determine its version tracking method. (Our current “principal method” may be assumed unless explicitly otherwise stated in the project’s ProjectParticulars.txt file—although you may not be able to check out that file until you know the correct method.)
When commitpropogting changes to source files, the provided check-in comments should do their best to describe:
Check-in comments should be brief, but we do not sacrifice useful content to brevity.
As close to the bottom of the file as possible, each source file should include the following (notice it is inside a comment):
/* $HeadURL:$ ** $LastChangedRevision:$ ** $LastChangedDate:$ ** $LastChangedBy:$ */
When the source file is checked into our Subversion source code management system, these lines will be expanded into the current file’s path, revision level and date/time of the last change. If the file ever gets “separated” (e.g., if a client returns it as an e-mail attachment), this portion of the file always contains sufficient information to check out the original from the Subversion repository for comparison purposes.
As a rule, we do not use Subversion’s Log keyword, which expands to include the full history of check-in comments for the file. If a project manager elects to use this keyword, it should be placed at the very end of the file so that the log information is available to anyone interested, but does not force readers of the code to page through years of modification history just to find the beginning of the source. Project managers should note that the Subversion documentation contains numerous warnings against using the Log keyword, especially with respect to problems created when a branch is merged onto the trunk. Caveat emptor.
Member variables in a class should follow an explicit access specifier, typically @private.
Typically, member variables should not be referenced directly, except within their accessor methods.
This simplifies changing a member’s type at a later date (if that becomes necessary).
In Objective-C we try to order and group our method declarations logically by topic. We place items of more general interest towards the top. For example, object propagation (i.e., allocation, initialization and reproduction) is just such a topic (and, typically, must happen before an object can be used), so all propagator declarations appear before other method declarations. Propagators appear before primitive methods (methods that directly access an object’s instance variables), and primitive methods appear before derivative methods (methods implemented via primitive methods). Private methods should not be declared in the interface file and, of course, member variables appear before method declarations. (See also our section describing how function definitions are ordered.)
When laying out classes in C++, we order the elements of each class as follows:
Member function declarations are listed first, separated into access specifier sections, in this order:
Member variables are listed next, separated into access specifier sections, in this order:
This places items of more general interest towards the top of the class definition. Each section should have an explicit access specifier and, within each section, we prefer to keep things grouped logically by topic. Because object propagation (i.e., allocation, creation and reproduction) is just such a topic (and must happen before an object can be used), all propagators appear together at the top of their respective access specifier section.
Refer also to the sections that discuss ordering function declarations and ordering function definitions.
Within the context of this document, propagators are those member functions (or methods) related to allocation, initialization and reproduction of objects. Within any given access specifier section, they always appear in this order:
In C++, because certain functions are supplied implicitly by the compiler (whether you want them or not), every class or struct definition must always either:
It is reasonable to have such declarations be private and unimplemented if objects of the type are not copiable.
Dependence upon any of the implicit constructor(s), destructor or operator= should always be documented using comments. Thus, if, for example, a destructor is never shown and no comment states that the implied (nonvirtual) default destructor is acceptable, a programmer can assume that the original author never considered the ramifications of the implied default destructor, and it may therefore be unreliable.
Whenever you add data members or base classes to a class, you must re-verify the status of these implied functions (and the initializer lists for every explicit constructor).
Friends (and derived classes) should never access data members directly. At the very least they should go thru private (or protected) access functions (that maintain a type’s invariant). This simplifies changing a member’s type at a later date (if that becomes necessary).
Any embedded (or contained) type in a class should be an abstract type (unless it is a primitive type or a concrete type that is part of an enclosed module). This decouples the enclosing class from the concrete types in other modules.
Function (or method) declarations should be grouped logically by topic or functionality (e.g., object propagation). Place functionality of more general interest towards the top of a class definition. Any function declaration that is not followed by a comment indicating its exception specification must be assumed to throw anything—if not as currently implemented, it may do so in the future.
In Objective-C, there is no point in duplicating an inherited method’s signature within a derived class’s declaration. Similarly, private methods should not be declared in the interface file.
See also our comments concerning ordering access specifiers and member declarations, and those concerning white-space and punctuators around logical groups of functions.
When programming in Objective-C, private and overridden inherited methods do not need to be declared in a type’s interface file.
They do, however, need to be declared/defined before their first use.
Because of how we order our function definitions, you should rarely have to predeclare private methods at the top of an implementation file.
If, however, it becomes necessary, do it above any @implementation blocks with an extension like this:
@interface YourClass ()
// Private method declarations here
@end
Generally, within an implementation file, function definitions appear in the same order as their declarations in the interface file. But what if a function (or method) is not declared in the interface file? As a matter of fact, in Objective-C, private methods should not be declared in the interface file making determining the order and placement of such “guidance-less” methods quite common.
Generally speaking, for functions not declared in the interface file, the function definition should be defined immediately above the definition of the topmost function that calls it. Overridden methods are special and should be grouped, according to the base class they were originally introduced in—and alphabetically therein—with those base classes closest to the root of the class hierarchy closest to the bottom of the file. Protocol conformance methods appear last of all. Observation methods typically appear in a section above that section that contains the designated initializer.
As an example, an implementation file for a NSView subclass might look something like this:
@implementation MyView
// MARK: As a MyView
- (void)specificToMyView
{
// Methods introduced in MyView appear toward the top.
// Private methods are typically above (or interspersed with) public methods.
// Methods introduced in MyView are ordered by functionality (just like the .h file).
}
// MARK: -
// MARK: - As an Observer
- (void)viewBoundsDidChange:(NSNotification*)notification
{
NSAssert(notification != nil, @"Expected valid notification");
NSAssert([[notification name] isEqualToString:NSViewBoundsDidChangeNotification],
@"Encountered unexpected notification (%@).", [notification name]);
// Respond to notification.
}
// MARK: -
// MARK: As an NSView
- (void)drawRect:(NSRect)rect
{
// Methods introduced in base classes are ordered
// alphabetically within their base class's group.
}
- (void)initWithFrame:(NSRect)frameRect // Designated initializer
{
// Alphabetically after -drawRect:.
// -init methods typically follow a pattern.
}
// MARK: -
// MARK: As an NSResponder
- (void)mouseDown:(NSEvent*)event
{
// Respond to -mouseDown:.
}
- (void)mouseUp:(NSEvent*)event
{
// Alphabetically after -mouseDown:.
}
// MARK: -
// MARK: As an NSObject
- (void)dealloc
{
// Dealloc members.
[super dealloc];
}
// MARK: -
// MARK: Conforms to NSDraggingDestination Protocol
- (BOOL)performDragOperation:(id<NSDraggingInfo>)sender
{
// Accept the drag.
}
// MARK: -
// MARK: Conforms to NSNibAwaking Protocol
- (void)awakeFromNib
{
// Do whatever.
}
@end
The above ordering takes a little extra effort initially to look up a class’s hierarchy, but looking for any given method becomes significantly easier as you become familiar with the various class hierarchies. This also tends to eliminate (or at least significantly reduce) the need for Private categories in implementation files in order to predeclare private methods.
See also our comments concerning white-space and punctuators around logical groups of functions.
Always explicitly declare a routine’s return type and parameter types. In other words, although:
SomeFnName();
may be compiler acceptable, it is also vague (especially so to the novice). However:
int SomeFnName(void);
is explicitly declared and always clear to everyone. Careful use of types can also go a long way toward declaring preconditions and postconditions.
Exception: In C++, an exception must be made for constructors and destructors, neither of which allows a declared return type.
Try to keep the number of arguments passed to a routine to “7(± 2)” (Miller) or less. If you have more than “7(± 2)”, consider making a ParameterBlock type struct (or a class) and passing a reference (or pointer) to the ParameterBlock. (The PowerPC calling conventions [cf. IM:PowerPC System Software p. 1-43] allow 8 general purpose registers [GPRs] and 13 FloatingPoint registers [FPRs] for parameter passing. Therefore, having more than eight non-floating point parameters would dictate that some parameters must be on the stack, which is less than ideal. Thus the rule should probably be “7(± 1)”.)
In C or C++, when declaring or defining a function, if a routine has only one parameter, fit it on the line with the routine name if possible. If a routine has more than one parameter, list them one parameter per line starting on the line following the routine name. This rule does not apply when calling a function.
Avoid passing routine parameter types by values larger than sizeof(void*).
Instead, pass either a pointer or a reference to the appropriate type.
This does not apply to built-in types because the compiler knows how to efficiently pass them.
A routine parameter type should always be an abstract (i.e., non-concrete) type unless:
This decouples the enclosing module from any concrete type’s module.
Always specify a routine’s formal parameter identifiers; never declare a routine with just a list of types as its parameters. Even when a formal parameter identifier is commented out (see below), it documents the intended purpose of the parameter.
When a parameter is not used in a routine (e.g., in an inherited member function which ignores a parameter useful to other derivatives), enclosing the parameter name in C style comments is a portable means of allowing you to use the name to document the parameter’s meaning while still avoiding “non-use” warnings. For example:
virtual void SomeFn(void* /*ioParam*/); // clearly ioParam is not used in
// this derivation of SomeFn()
It is also acceptable to use #pragma unused (ioParam) to suppress the “non-use” warnings.
An obvious exception to this convention would be providing a name for the int argument for operator++(int) to indicate postincrement.
(Of course, operator++(int /*postIncrement*/) does make the declaration even clearer.
Hint! ;-)
Functions cannot rely upon callers to be well behaved, therefore every function should validate that all passed in arguments are correct and flag incorrect usage. In particular all pointer parameters, regardless of whether they are optional or not, must be verified as not zero before dereferencing them.
Exception: Because the compiler always passes a valid object pointer, self (or this) can be dereferenced with impunity.
Non-optional (i.e., required) pointers should present some sort of debugging signal—and maybe even abort execution—(or throw an exception) when a passed in pointer is zero. Optional pointers will need to be tested (quite naturally) as part of the code.
Routines that merely pass along a pointer to another routine (and therefore never actually dereference the pointer), do not need to verify whether the pointer is non-nil (because the ultimate user is presumed to do that).
Exception: Unfortunately, some Cocoa framework methods will crash if you pass in an invalid value. As a result, it is useful to validate arguments before they are passed to most Cocoa methods. Better to be safe than sorry.
Every otherwise ambiguous formal parameter identifier should begin with one of three prefixes (viz., ‘in’, ‘out’ or ‘io’) describing how the routine will use the actual argument the caller passes to the routine.
When writing code for C++, if an ‘in’ type parameter is not optional, i.e., a nil pointer would have no meaning for the routine, use a reference to a const type instead of a pointer to const type. In other words, the only reason to accept a const type as a pointer would be if the value is optional; in such a case the identifier should probably have the ‘OP’ suffix or some other comment indicating the pointer can be nil.
Within a routine body, the routine’s integral return value is often a local variable, and it does not have ‘out’ as a prefix.
Comments for a routine that has a parameter with an ‘io’ prefix may use the ‘in’ or ‘out’ prefixes (instead of ‘io’) to distinguish what the routine expects as input from what it will deliver as output. For example:
void SomeFn(SomeType* ioParam); // inParam can comment input;
// outParam can comment output.
In C and C++ there are typically some predefined typedefs, for example, SInt8, UInt16, and SInt32, for use when referring to integral types.
These typedefs provide an easy way to specify the size of an integer variable in a cross-platform manner.
We typically discourage use of these types because it conditions people to think in terms of representations and sizes, instead of types and maximum/minimum values. (Cf. Item 91 of [Sutter2005a].) Instead, we encourage our programmers to learn “what the standard allows” for the integral types and base their typing decisions on that.
Of course, if you are declaring a variable to pass to a library interface that uses these predefined data types, by all means, use the same type.
“There are only two hard things in Computer Science: cache invalidation and naming things.”
—Phil Karlton
One of our main activities as programmers is giving names to things. The most important principle we follow is that identifiers should be descriptive, memorable, self-documenting and of unambiguous meaning. Do not do this:
long xx;
long xx1;
float xx2;
Instead, prefer meaningful variable names:
long elementCount = 0;
long xPosition = 0;
float currentTemperature = 0.0;
Try to make an identifier representative of the highest level of abstraction commensurate with its context.
(When naming things, context is very important.)
If you have to insert a comment to explain an identifier’s meaning, you probably need to rename the identifier.
(Comments about units of measure and the like are acceptable but it would be better to have the identifier’s “type” document such units, if feasible.)
As much as possible, reduce an identifier’s cognitive load—i.e., the effort required by a client to understand, remember and use the identifier.
Generally, the shorter an identifier’s life (or the more localized its scope), the shorter its name may be.
For example, the traditional use of i and j as loop index names are idiomatic and their use is not to be discouraged.
As you name things, you will also probably want to be aware of, and comply with the AppleScript naming rules. (You will want to pay particular attention to the subsection discussing language keywords to avoid.)
Any identifier of a Boolean type, whether for a variable or a function name, ought to begin with an interrogative (i.e., a word that introduces a question, such as “is” or “has”).
For example: hasColor, isLightOn, isEmpty.
This makes if statements that use these identifiers easier to understand.
See also ”Explicit is Better Than Implicit” below, as well as the KVC discussion.
All functions that accept parameters passed as pointers are assumed to not accept zero, NULL or nil for the pointer argument unless there is a comment in the interface file (or other documentation) to the contrary.
Such a comment may consist of simply appending the ‘OP’ suffix to the formal parameter’s name.
Functions that do not accept a nil pointer should contain an assertion early in the function that validates that the passed in pointer is non-nil so that client programmers who do not read carefully learn about their mistake.
Numeric literals (other than 1 or 0) should only appear in static constant or enumerator declarations; i.e., “avoid magic numbers”.
In the same way that we centralize our magic numbers, we centralize our embedded strings.
The only string constants that should appear directly in code should be those supplied as explanations of assert()-style statements.
By establishing a simple set of capitalization standards, we can eliminate large amounts of time wasted trying to remember how to spell an identifier declared elsewhere in the source.
Instead of using the words_separated_by_underscores style found in many programming textbooks, all identifiers in our programs use one of several mixed case formats, as outlined below.
(See also Reserved Prefixes.)
enum IceCreamFlavor
{
kVanilla = 0, // always initialize the first enumerated value
kChocolate,
kRockyRoad,
kFudgeChunksAndChips // note: no comma on the last enumerated value!
};
typedef std::vector<PinnedSpliceImpSPtr> VectorOfPinnedSplices;
Function names, whether a class member or not, begin with an uppercase letter, and all subsequent words are also capitalized.
loadDataRepresentation:ofType:.
goto statements are named using a leading uppercase letter, with subsequent words also capitalized.
See Indentation for an example.
void
SomeFunction(int typicalParam)
{
std::string fileName;
short xPosition;
//...
}
class SomeClass
{ //...
std::string mFileName;
short mXPosition;
}
self.
struct Point
{
float xPos;
float yPos;
};
Identifiers should not contain underscores. Most identifiers that contain underscores are reserved to the implementers of the C language (and thus to the implementers of all languages that derive from it). The rules reserving such identifiers are quite complex but the following exceptions are known not to violate them.
mNASAData, not mNasaData.
class MegaSurfApp;
void About(int megaSurfVersion);
const keyword, as an enumerator in an enumeration type, the Java final keyword, or other equivalent mechanism.
Note that the “k” prefix is only intended to apply to identifiers that are constant at compile-time. Do not write code like:
void SomeFunc(const std::string& kParam); // Bad
This should instead be:
void SomeFunc(const std::string& param); // Better
See also the ”r” prefix below for compile-time constant resource identifiers.
private static final qDebug = false;
if (qDebug)
{
// Useful debug-only code here...
}
is the logical equivalent of C/C++ code like:
#define qDebug 0
#if qDebug
// Useful debug-only code here...
#endif
Because #define causes replacement at preprocessor time (independent of the overriding language’s rules), it is inherently dangerous and really only suitable for including/excluding code at preprocessor time.
If the language you are using has some other, better mechanism (such as inlining or the const keyword), never use #define for defining a macro or a constant.
The only exception is when the macro is used during debugging but removed from release code, such as with the assert() macro.
#ifndef FileName_h
#define FileName_h
//
// Contents of file here...
//
#endif /* FileName_h */
// The above line must be the last non-comment line in a header file.
The identifier that precedes the “_h” suffix should be the name of the file, without its file extension. (This is one of the few exceptions to the ”Identifiers never contain underscores” guideline.)
Include-guard preprocessor directives are less efficient than “#pragma once” (because they can not skip the overhead of reading and parsing the included files), however they are necessary so files will work with compilers that do not recognize “#pragma once.”
In source code, use only those abbreviations that are in the accepted Abbreviations list or those that are obvious, common, or idiomatic to the project (and thus specifically designated as acceptable in the ProjectParticulars.txt file). If you are too lazy to learn the accepted abbreviations, avoid using abbreviations at all.
When abbreviations are used in source, it is important to take care to prevent confusion arising from oddly chosen abbreviations, or from inconsistent use of them.
For example, if you have decided that index is just too many letters to type as part of identifier names, decide once for the project whether you are going to spell it indx or idx and use that consistently throughout the project’s code.
Because Cocoa’s “bindings” technology (as well as its implementation of AppleScript) relies on Key-Value Coding (KVC), it behooves us to follow a style that is fairly consistent with the requirements of KVC. KVC requires following a simple set of conventions for naming accessor methods, briefly summarized here. (Capitalization here reflects that of Objective-C. In C or C++, function names would, of course, begin with upper case letters. Our ‘keys’ would also most likely have an “m” prefix, which would be ignored when determining the actual ‘key’):
A “set” accessor method should always appear immediately above its “get” accessor counterpart (when both exist). This is easy to remember because you must “set” a given value before it makes sense to “get” it.
We never use (and strongly discourage) Hungarian notation.
Since more time is spent reading code than writing it, having clear, thorough documentation is crucial; both during initial development and for successful long-term maintenance. The goal is not redundancy; commenting every line of code like this:
// Increment i by 1
++i;
…just raises the noise floor and provides no useful information. However, comments like:
bool
AddMidiEvent(MidiEvent event)
{
// Add the time-stamped MidiEvent 'event' at the correct place in our
// event list. We are using an array representation of a heap structure
// (see Sedgewick, "Algorithms in Java", chapter 9). This algorithm is
// guaranteed to be at worst O(2 log(n)).
// Code left as an exercise for the reader....
}
…explains the approach and rationale of the code that follows, along with a pointer to an external reference explaining the design and theory behind the underlying data structure.
The primary function of comments in interface files is to provide the necessary documentation for client programmers who will be using the interface. Ideally, client programmers should never need to refer to an interface’s implementation details to make proper use of the interface.
Make sure that the following things are well and correctly commented:
General comments related to the entire interface should be placed immediately below the copyright notice. Comments detailing the interface’s primary class should be placed either: a) immediately following these general comments, or b) immediately preceding the primary class’s definition. Within interface files that define more than one class, comments detailing the subsidiary classes should be placed either: a) immediately following the primary class’s comments (if they appear immediately under the copyright notice), or b) immediately preceding each subsidiary class’s definition.
Comments detailing a specific function (or its parameters or return value) should appear immediately following the function’s declaration.
Each function declaration is expected to document the failure guarantee its implementation promises. Therefore:
// throw()” commented exception specification after the function declaration.
Ideas for how this could be documented in Objective-C are welcome.
In languages that do not use separate interface files, the same principles apply; the interface must be documented at a sufficiently high level for clients of the code.
The primary audience for comments in implementation files is the maintenance programmer(s) who will be working on your code in the future. Most likely, that maintenance programmer will be you, which should give you extra cause to be charitable with your comments. (As an aside, it is a good practice to, periodically, go back and try to comprehend code you wrote six months ago or more. It helps teach you the types of comments that are useful and those that tend to be superfluous.)
Comments typically precede the code being documented, and are at the same level of indentation. The comments should not just echo the code in prose, but should discuss the intent of the code. In Code Complete, McConnell recommends implementing functions by writing the comments first, then going back and actually writing the code. The approach is sound—if you do not understand the requirements of the function well enough to write it as a narrative first, you do not yet have a firm enough design to write code from.
Xcode detects comments beginning with certain character sequences and treats them specially. (And because the sequences are standard, being able to search all files for occurrences has its uses as well.) The character sequences are:
// MARK:
// TODO:
// FIXME:
// ???:
// !!!:
Capitalization is critical, and both the colon and (unseen) space character (following the colon) are essential.
A comment beginning with ‘MARK: ’ is treated just like #pragma mark (but does not cause problems in cross-platform code) and Xcode places the text following the space character in the function pop-up menu.
(If “the text following the space character” is a single hyphen followed immediately by a carriage return, a separator line is added to the function menu.)
Comments beginning with the other four character sequences cause the character sequence and the text following the space character to be added to the function menu.
Comments beginning with the ‘MARK: ’ character sequence are clearly the most common (as seen in the sample NSView subclass), however, although of a more temporary nature, we should not disregard the other character sequences.
For example, consider these possibilities:
// TODO: Revisit -dealloc to ensure it releases all alloced objects
// FIXME: Temporarily forced hideBorder flag to NO to exercise that code path
// ???: Jack, is this code correct?
// !!!: Not all code paths in this method have been thoroughly tested
When using these latter four character sequences, carefully consider whether they should be accompanied by some sort of #warning statement so that every build makes it clear that their concerns still need to be tended to.
All indentation is done using literal tabs (0x09), not space characters (0x20).
We use four spaces per logical tab stop, and we indent wrapped lines by eight spaces.
Set your editor to always save files in this format.
Preprocessor directives and labels used as the target of a goto statement are always placed in the first column, regardless of the current ambient indentation level:
{
bool ok = true;
for (int i = 0; i < kSomeConstant; ++i)
{
for (int j = 0; j < kSomeOtherConstant; ++j)
{
#ifdef qVerbose
std::clog << "Testing: " << i << ", " << j << std::endl;
#endif
ok = this->Test(i, j);
if (!ok)
{
std::cerr << "Fatal error testing: " << i << ", " << j << std::endl;
goto Cleanup;
}
}
}
Cleanup:
// Cleanup code here...
return ok;
}
When preprocessor directives are heavily nested, some indentation, typically with space characters, may be necessary to improve clarity. Additional comments and examples on indentation are spread throughout these guidelines.
Avoid using source lines longer than 90 characters. Occasional violations of this item are acceptable when the resulting code avoids an awkward line break or is otherwise more readable as a single long line. (Eliminating compound statements can help.) Very long lines due to deep indentation levels may be a sign that deeply nested code should be refactored out into a separate function.
If the project is being developed in Xcode (or some other development environment that automatically wraps lines), it is not necessary to manually break a line. However, there are times, when doing so may make code easier to read. When you do this, bear in mind the 90-character limit. Don’t go breaking lines and indenting such that there are less than 45 information-bearing characters before the end-of-line break at (approximately) the 91st character position.
Logical lines that are longer than 90 characters should be broken at the most logical point and continued on the next line, indenting eight spaces (i.e., two logical tab stops):
1 2 3 4 5 6 7 8 9
123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890
retval = FunctionWithManyArguments(longArgumentName1, longArgumentName2,
longArgumentName3, longArgumentName4);
This “double” indentation prevents confusion over whether the indented line is part of an indented logical construct, which is typically indented one logical tab stop. An alternative layout that is taller rather than wider is:
NSBeginAlertSheet(
NSLocalizedString(@"Dialog title", nil), // title
NSLocalizedString(@"OK", nil), // defaultButton
nil, // alternateButton
nil, //otherButton
docWindow, //docWindow
self, // modalDelegate
nil, // didEndSelector
@selector(sheetDidDismiss:returnCode:contextInfo:), // didDismissSelector
nil, // contextInfo,
@"String detailing message"); // msg
The advantage of using this tall layout is that it makes it easy to add comments that identify each of the arguments made to a function having a large number of parameters, especially when more than one argument is nil. This should only be needed rarely because your variables are well named, right?
Lines containing expressions should be broken as naturally (i.e., as like English) as possible. Where possible, keep all of a routine call on the same line, otherwise break after the space that follows a comma:
if (anObject.IsObjectOfThisTypeReadyFor(crucialParameter, someOtherCurcialParameter)
&& anObject.HasWhatWeNeed())
{
retval = anObject.SomeOtherUsefulFunction(x.LeftMargin() + x.RightMargin(),
x.TopMargin() + x.BottomMargin() - 1);
}
while (someVariable >= someOtherVariable && someVariable <= someThirdVariable)
{
setSomeVariable = SomeComplicatedFn(Parameter1, value1 + value2,
Parameter3);
if (setSomeVariable <= SomeConstant)
{
someVariable += SomeConstant;
someOtherVariable = someVariable
+ SomeFnReturningAValue(SomeParameter);
}else
{
SomeOtherVariable = someVariable + someOtherVariable
+ SomeFnReturningAValue(someParameter);
// Multiple line logical block (which the syntax doesn't require braces around);
// enclose anyway because it is multi-line.
}
}
When that is not feasible, breaking after the space that follows an operator is similar to English’s use of hyphens to indicate a word break. Only use the backslash ‘\’ line-continuation mechanism when it is not possible to find a cleaner place to break. As McConnell puts it in Code Complete:
Make the incompleteness of a statement obvio .
Ironically, although I understand the logic of the above “operator acts as hyphen” guideline, it is not what I prefer in code. Personally, when I cannot break after the space that follows a comma, I prefer to break after the space that precedes an operator. Normal code statements rarely begin with an operator, and therefore, when a line begins with one, it (in conjunction with its double indentation) can easily be recognized as a clue that the line is a continuation from the line above.
retval = anObject.SomeUsefulFunction(x.LeftMargin() + x.RightMargin()
+ anObject.HorizontalPadding(), x.TopMargin() + x.BottomMargin() - 1);
if/else blocksfor()while()do/while()switch()try/catch blocksMember variables (and, in C++, base classes) should be initialized in their declared order to simplify verification that all members actually get initialized. (When using C++, always use an initializer list.) In languages that preinitialize member variables to some value (such as Objective-C, which preinitializes members to zero), actual initialization may be skipped but you should add an assertion to document (and validate) the default value. A member variable missing from a constructor or initializer indicates that the original engineer failed to consider its initialization.
Initializer methods in Objective-C typically follow a pattern.
Because the languages we use do not guarantee the evaluation order for arguments passed to function calls, caution must be exercised when writing expressions as part of a function or method call. In particular, resource acquisition and assumption of ownership of the resource should be a statement unto itself and never combined with a function call (including as an operand of an operator, which may be overloaded and thus a function call).
if/else blocksPlacing an else on the same line as the closing brace of a previous compound statement makes it clear that the previous compound statement is not the end of the entire construct, only an intermediate subdivision thereof.
When an if immediately follows an else, place them on the same line, thereby providing a visual clue to clients that the previous construct is continuing.
if (someBooleanExpression)
{
// Code to execute when true
}else if (someOtherBooleanExpression)
{
// Some other code to execute
}else
{
// Code to execute in other cases...
}
for()
for (int i = 0; i < kSomeConstant; ++i)
{
// Loop code here...
}
Note that we prefer to use the preincrement ++i as a general habit.
In all languages that use this construct, it is guaranteed to work identically to the more commonly seen postincrement i++ that dates back to the earliest days of the C language.
In C++, however, maintaining this habit prevents possible inefficiencies when looping over an object that exposes an iteratable interface.
Consider the likely cost difference between:
typedef std::vector MyVector;
MyVector vec;
// Assume the vector gets filled here....
for (MyVector::const_iterator i = vec.begin(); i != vec.end(); i++)
{
// Important code here...
}
and:
MyVector::const_iterator vecEnd = vec.end();
for (MyVector::const_iterator i = vec.begin(); i != vecEnd; ++i)
{
// Important code here...
}
Although it is impossible to know how complex post-incrimenting i is, it is always guaranteed to be no better than preincrementing.
Even though Knuth said:
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
…one of the benefits of building up habits is that they let us forget things, but still obtain their advantages. As Sutter says, “This is not premature optimization; it is avoiding gratuitous pessimization.”
while()
while (someBooleanConditon)
{
// Useful code...
}
If the body of the while() is empty, make that explicit, as:
while (isWaitingForSignal())
{
// Do nothing
}
not:
while (isWaitingForSignal()); // Easy to overlook
do/while()
do
{ // Loop code here...
}while (someBooleanConditon);
switch()The optimal layout of case statements inside a switch statement is shown here.
It is visually appealing and provides an easy way to declare local variables that are restricted to the scope of an individual case.
switch (verticalPositionOnPage)
{
// Comments precede the case, or can be inside the case's block
case kBottom:
{
[self preventCropMarks];
[self doWhatsAppropriateForBottomOfPage];
}break;
case kMiddle: // No need to include a commented out break when falling through an empty case
case kVerticalCenter:
[self doWhatsAppropriateForVerticalOfPage];
break;
case kAboveTop:
{
unsigned adjustedDist = [self cropMarkAdjustment];
[self compensateForCropMarks:adjustedDist];
}// Fall thru // *Always* document intentionally falling through.
case kTop:
{
[self preventCropMarks];
[self doWhatsAppropriateForTopOfPage];
}break;
default:
NSAssert1(NO, @"Encountered invalid switch case (%d).", verticalPositionOnPage);
break;
}
Switch statements should always have a default case.
If the default case should never be executed, place an assert(!"Invalid switch case"); statement in the default case to make sure that this error is caught during debugging and testing.
try/catch blocksPlacing the catch on the same line as the closing brace of a previous compound statement makes it clear that the previous compound statement is not the end of the entire construct, only an intermediate subdivision thereof.
In C++:
try
{
// Code to execute under "non-exceptional" cases
}catch (std::exception& except) // Note: Caught by reference
{
// Deal with std:exception
}catch (...)
{
// Deal with any non-standard exception
}
In Objective-C:
@try
{
// Code to execute under "non-exceptional" cases
}@catch (NSException* exception)
{
// Deal with NSException
}@finally
{
// Code that executes, regardless of whether an exception is thrown or not
}
Do not rely on the fact that many operations may silently be coerced, by the compiler, into a Boolean condition. Always make the comparison explicit:
if (pointer != NULL)
{
// Code...
}
not:
if (pointer) // Bad
{
// Code...
}
However, if you are in fact working with real Boolean values, there is no need to labor the point—code like:
if (HasColor())
or:
if (!HasColor())
is fine—you do not need to write code like:
if (true == HasColor()) // Cumbersome
or:
if (false == HasColor()) // Cumbersome
Declare variables as close to the point of first use as possible, rather than in a single big block at the top of the current scope (unless you are programming in ANSI strict C).
Only declare one variable per line of source code—do not do this:
// NOTE that the following line of code is probably not what the programmer
// intended to write, as 'xPos' is a pointer-to-int, but 'yPos' is an
// int. At the least, it is confusing for the quick reader.
int* xPos, yPos;
double yaw, pitch, roll;
Instead, do:
char* xPos = NULL;
char* yPos = NULL;
double yaw = 0.0;
double pitch = 0.0;
double roll = 0.0;
Avoid leaving variables uninitialized, thereby avoiding the possibility of errors resulting from those variables being accessed while filled with garbage.
White-space and punctuators should typically be used in ways similar to how they are used in English, viz.:
break; or return;for() loop), the semicolon is followed by a space.
( and [ are not followed by a space, and ) and ] are not preceded by a space.
An exception to this may be made to make grouping more apparent when using deeply nested parentheses:
if ( ((a == b) && (c == d)) || ((e == f) && (g == h)) )
const char* kSome_CString = "Some string";
Because of a programming language’s mandatory syntax, we have to make some exceptions to the “ways similar to English” general rule:
SomeFn(parameter);
someArray[1];
static_cast<sometype>(someObject);
char* buffer = 0;
void SomeClass::SomeClass(const SomeClass& x);
not:
// Don't do this:
char *buffer = 0;
void SomeClass::SomeClass(const SomeClass &x);
// Or this:
char * buffer = 0;
void SomeClass::SomeClass(const SomeClass & x);
Although “a dereferenced buffer” can be thought of as a char, more properly buffer is a “pointer to char.”
The buffer variable is what is being initialized, not the first char referred to by *buffer.
As an aside, when using a code editor that automatically wraps text, like Xcode, having the * and & attached to the type name prevents the wrapping mechanism from breaking a line in an odd place for some constructs in some languages. Take for example this oddly broken up Objective-C declaration:
// Don't do this:
-(void) selectRow:(int *)selectedRow andColumn:(int *) amongstNRows:(int
*)rows andNColumns:(int *)columns
SomeClass::SomeFn();
::SomeGlobalFn();
someObjectP->SomeFn();
someObject.SomeFn();
operator keyword acts as a prefix.
Separating the operator keyword from the operator designator makes the declaration look like an expression.
Matching curly braces should always be aligned in the same column, with all code inside the braces indented one logical tab stop. In general, this means that curly braces should always be on a line by themselves:
if (someBoolean)
{
someVariable += 1;
}
not:
if (someBoolean) {
someVariable += 1;
}
Some common exceptions to the “braces alone on a line” rule are found when using an else clause, a do/while loop, or a catch clause.
Placing the closing brace and the else, while or catch clauses on the same line, immediately following the brace (with no space between), makes it clear that the while, catch or else expressions are a continuation of the preceding scope, which would not otherwise be visually obvious.
In general, to avoid maintenance problems in the future, prefer to use curly braces even in situations where the language does not require their use, such as very simple if/else statements or for loops:
if (someBoolean)
{
FunctionCall();
}
for (int i = 0; i < kLimit; ++i)
{
fbuffer[i] = 0;
}
not:
if (someBoolean)
FunctionCall();
for (int i = 0; i < kLimit; ++i)
fbuffer[i] = 0;
Another case where “unnecessary” braces should be used is when writing an empty while loop:
while (*p++ = *q++)
{
// This loop intentionally left empty.
}
instead of the form that is more commonly found in books:
while (*p++ = *q++); // <-- Semicolon easy to overlook
By prohibiting this common loop format, we can easily check for cases where legal (but wrong) code:
int i = 0;
while (i++ < kLooplimit);
{
mybuffer[i] = 0;
}
performs a loop with no body, then executes the intended body of the loop exactly once.